Reducing Kafka costs with Z$tandard
One of the major challenges that technology startups will face is scaling up effectively and efficiently. As your user base doubles or triples, how do you ensure that your services still run smoothly and deliver the same user experience? How do you maintain performance while being cost-efficient? Here at Amplitude, our customers have tracked more events in the past year than in the first 3 years of our company combined. As we and our customers grow, we need to continue providing the same if not better service across our platform. Previously, we explained how Nova, our distributed query engine, searches through billions of events and answers 95% of queries in less than 3 seconds. In this blog post, we will focus on our data processing pipeline that ingests and prepares event data for Nova, and explain how we stay cost-effective while our event volume multiplies.
Our data processing pipeline is a multi-step system involving two processing clusters and two Kafka clusters. The data upload endpoint hits an autoscaling event server cluster that dumps the raw data to our first Kafka cluster. Next a larger autoscaling cluster, which we fondly call Megatron, transforms and normalizes the raw data. Megatron is also where we provide most of our processing guarantees, such as merging users, syncing user properties, and removing duplicate events. Megatron then dumps the normalized data into another Kafka cluster, which is the entry point into our lambda architecture.
Our event volume is very cyclical, rising in the morning and falling early in evening. Having autoscaling clusters allows us to minimize any wasted instances and processing power. Aside from instance costs, another big EC2 cost is data transfer. It costs $0.02 per GB when sending data between EC2 instances in different AWS regions. This might not seem like much at first, but it can quickly add up when you have hundreds of instances across multiple zones and regions, all transferring hundreds of terabytes of data per month. Fortunately, the raw event data going through our data ingestion pipeline is in JSON, making it a good opportunity to use data compression to reduce data transfer costs.
Enter Zstandard

Back in August of 2016, Facebook announced a new compression algorithm called Zstandard, which promised the same compression ratio as zlib at much faster compression and decompression speeds. In addition, Zstandard also offers a number of compelling features, such as:
- 22 compression levels for granular control over compression speed and ratios
- Parallel processing optimizations
- Training on a dataset to derive a dictionary file that can improve the compression speed and ratio for future data
At the time of Zstandard’s release, we were compressing our JSON event data using LZ4, which provided a reasonable compression ratio (around 2–2.5 in production) and a fast throughput speed. Our event JSON is highly structured in that we expect the same set of keys for all events and values that often repeat across multiple events. In addition, we process events in small batches (3–4 events per batch on average), making it difficult for standard “learn-as-you-go” type compression algorithms (like Zlib, LZ4, and even untrained Zstandard) to achieve optimal performance. This is the perfect use case for Zstandard’s dataset training capability. You only need to learn the data once, and then you can effectively apply the results to all compressions and decompressions, regardless of the data size.
The benchmarks on Facebook’s blog post indicate that Zstandard is able to provide roughly a 50% better compression rate over LZ4, albeit at a slower compression speed. We decided to measure Zstandard’s performance on our data to see if it was a viable alternative to LZ4. These were our goals for the benchmark:
- See if Zstandard’s slower compression and decompression rate (compared to LZ4) would impact the overall throughput of our data processing pipeline
- Compare Zstandard and LZ4’s compression rates on production data
- Determine the ideal compression level and dictionary size to use for Zstandard
Initial Benchmarks
To start we dumped a representative sample of 250,000 raw events to a JSON file. Next we loaded all of the events into memory, and recorded the time to compress and write all the events to an output file. To compute the compression ratio we compared the size of the output file to the size of the raw event JSON file.
Base benchmark for LZ4:
- Compression Time: 8.202 seconds
- Compression ratio: 2.466
Next we benchmarked Zstandard with various compression levels without any training:
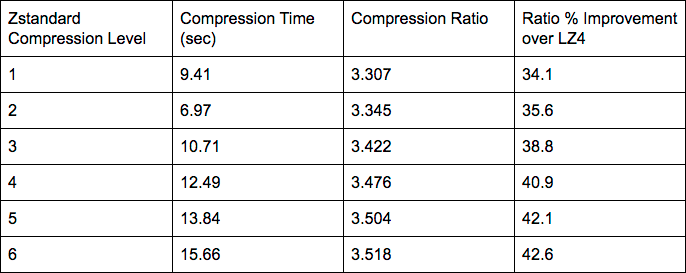
The initial results were promising. With a compression level of 3, we were getting a 38% improvement in the compression ratio over LZ4, with almost the same compression time.
What happens if we then train Zstandard? Training Zstandard allows it to generate a dictionary file, which you can use while compressing and decompressing. One of the tunable parameters is the size of the dictionary file. A larger training dictionary output might contain more compression information and yield better performance; however, the tradeoff is you have to hold a bigger file in memory. Another one of our goals was to determine which file size was ideal for our use case.
We grabbed another small sample of raw JSON events to use as the training set, and started benchmarking with a 16kb dictionary file:

These results are already looking pretty good. We were getting more than double the compression ratio at the same throughput with just a small dictionary file. We continued benchmarking the compression ratio and speed with various compression levels and dictionary file sizes:
From the results it seems that there are diminishing returns with higher compression levels and larger dictionary file sizes. The 256kb and 512kb files offer only slightly better compression ratios over the 128kb file, but at higher compression levels their compression speed is significantly slower. We initially settled with using the 512kb training file with a compression level of 3 because it offered a comparable compression time while getting almost a 3x better compression ratio over LZ4.
Results
Shortly after deploying to production, we experimented with the compression level. Even though our initial benchmarks showed significantly slower compression speeds at higher compression levels for a 512kb dictionary file, we were actually able to increase the compression level to 10 without any noticeable impact to the processing throughput speed. Above 10, however, and Zstandard began to affect CPU usage and processing times. Depending on your pipeline and architecture, you may find that you are able to increase the compression level without creating a bottleneck in your system.
After switching to Zstandard, our bandwidth usage (see above graph) decreased by 3x! That’s huge! This saves us tens of thousands of dollars per month in data transfer costs just from the processing pipeline alone. With these great results we immediately began deploying Zstandard to other systems in our architecture for further cost savings.
One thing to mention is that you have to decompress data with the same dictionary file used to compress it. We built a small internal wrapper around Zstandard to add some basic versioning around the dictionary files, and when compressing data we prepend the dictionary file version to the Zstandard magic number (compressed results all begin with Zstandard’s 4 byte magic number header). That way we can easily add and deploy new versions of each dictionary file, and the wrapper will figure out the appropriate one to use.
Zstandard is a great tool to use if you are transferring high volumes of data through many levels of your stack. We’ve been using it in production now for several months without any issues, and it has allowed us to continue growing efficiently. Our event volume has more than doubled over the past year, but we are still far from needing to scale up our Kafka clusters. Many thanks to the Facebook team for releasing Zstandard!
If you are interested in reading more, check out our engineering blog. If you’re excited about working on problems like this, please reach out to us at careers@amplitude.com!

